J'ai demandé à l'IA de coder mon backtester… ça a marché ???
Algo Trading
Tout sur le framework de backtest Python que j'ai construit avec Claude Code — et comment backtester n'importe quelle stratégie depuis un seul prompt. Couvre l'architecture du moteur cash-flow, le fichier CLAUDE.md, la prévention de l'overfitting, et une démo live : MA Crossing 20/50 sur SPY (2000–2026), +17,0% de return total, Sharpe -0,08, 138 trades — avec l'audit complet par l'IA de pourquoi le résultat est mauvais et quoi corriger.
Antoine
CEO - CodeMarketLabs
2026-05-16
Je n'ai pas écrit ce framework. Pas vraiment. J'ai décrit ce que je voulais à Claude Code — un moteur de backtest propre avec gestion des positions, mark-to-market et risk sizing basé sur le stop loss — et il l'a construit. Cet article couvre l'architecture complète, comment le fichier CLAUDE.md transforme l'IA en développeur junior sur votre projet, et une démo live : une stratégie MA Crossing 20/50 complète sur SPY, générée depuis un seul prompt, exécutée sur 26 ans de données, et auditée en quelques minutes.
Ce que couvre cet article
Ce qu'est un backtest et pourquoi l'approche cash-flow est supérieure à la simulation vectorisée.
Comment structurer vos données pour éviter les biais : dividendes, splits, qualité des sources.
Comment éviter l'overfitting avec une validation walk-forward et du front-testing Monte Carlo.
L'architecture du framework : DATA SOURCES → CORE ENGINE → STRATEGIES → OUTPUT.
Comment le fichier CLAUDE.md permet à Claude Code de générer une stratégie complète depuis un seul prompt.
Audit complet du MA Crossing 20/50 sur SPY (2000–2026) : +17,0% de return total, Sharpe -0,08, 138 trades — et ce que ce résultat vous dit vraiment.
1. C'est quoi un backtest — et pourquoi l'approche cash-flow change tout
Un backtest, c'est simple : vous prenez une règle de trading et vous l'appliquez mécaniquement à des données historiques. À chaque barre depuis le début de votre dataset jusqu'à aujourd'hui, vous appliquez votre signal, ouvrez ou fermez des positions, et suivez ce que votre portefeuille aurait valu. Le résultat, c'est une equity curve — la valeur de votre portefeuille dans le temps. Cette courbe vous dit tout : est-ce que vous avez un vrai edge statistique, ou est-ce que vous tradez un mythe.
Il y a deux grandes approches d'implémentation. Le backtest vectorisé calcule les signaux sur l'ensemble du dataset en une seule opération matricielle — rapide, mais il masque les frictions et rend difficile le suivi de l'état réel de votre cash à chaque instant. L'approche cash-flow, que ce framework implémente, simule le portefeuille barre par barre. À chaque barre : cash en entrée, cash en sortie, positions mark-to-market. La valeur du portefeuille à tout instant c'est le cash plus la valeur de marché des positions ouvertes — exactement comme un hedge fund calcule sa valeur liquidative. Ça compte dès que vous avez du cash non investi, plusieurs positions simultanées, des frais, et l'effet cumulatif de tout ça dans le temps.
On peut aussi aller au-delà des données historiques avec ce que j'appelle le front-testing : générer des chemins de prix synthétiques via simulation Monte Carlo et mesurer la performance de la stratégie sur des centaines de régimes de marché différents. Ça répond à une question différente — pas 'est-ce que ça a marché dans le passé ?' mais 'dans quelles conditions cette stratégie fonctionne-t-elle vraiment ?'
2. La qualité des données : le fondement de tout backtest honnête
Avant de pouvoir backtester quoi que ce soit, il faut des données propres. Propres veut dire : disponibles sur la période cible, à la fréquence cible, sur les instruments cibles, et exemptes d'événements corporatifs qui corrompent les séries de prix. Les dividendes et les splits créent des sauts artificiels dans les données non ajustées qui génèrent de faux signaux dans toute stratégie utilisant des niveaux de prix bruts ou des moyennes mobiles. Utilisez toujours les cours ajustés.
Pour la plupart des cas d'usage, Yahoo Finance via la librairie Python yfinance est un point de départ solide — cours ajustés sur des milliers d'actions, ETF, indices, gratuitement, sur 20+ ans. Le module yahoo_data.py du framework gère le téléchargement, la normalisation des colonnes et le cache automatiquement. Pour des données haute fréquence, des chaînes d'options ou des données futures plus précises, des fournisseurs dédiés sont nécessaires. Une liste des API que j'utilise est disponible sur ma page outils.
3. Le piège de l'overfitting
L'erreur la plus fréquente en backtesting, c'est l'overfitting : choisir des paramètres qui auraient maximisé le P&L sur vos données historiques, puis découvrir que la stratégie échoue dès qu'elle voit de nouvelles données. Il est facile de construire une stratégie qui semble parfaite en rétrospective. La partie difficile, c'est d'en construire une avec un vrai edge qui tient hors échantillon.
La mitigation standard consiste à diviser votre dataset en deux fenêtres non chevauchantes. La fenêtre in-sample sert à la conception de la stratégie et à la calibration des paramètres. La fenêtre out-of-sample est mise de côté et utilisée une seule fois pour la validation finale. Si la stratégie fonctionne in-sample mais échoue out-of-sample, vous avez un overfit. Pour aller plus loin, le front-testing Monte Carlo — générer des milliers de chemins de prix synthétiques avec différents régimes de volatilité, niveaux de drift et structures de sauts — permet de stress-tester la stratégie dans des conditions qui n'ont peut-être jamais figuré dans vos données historiques.
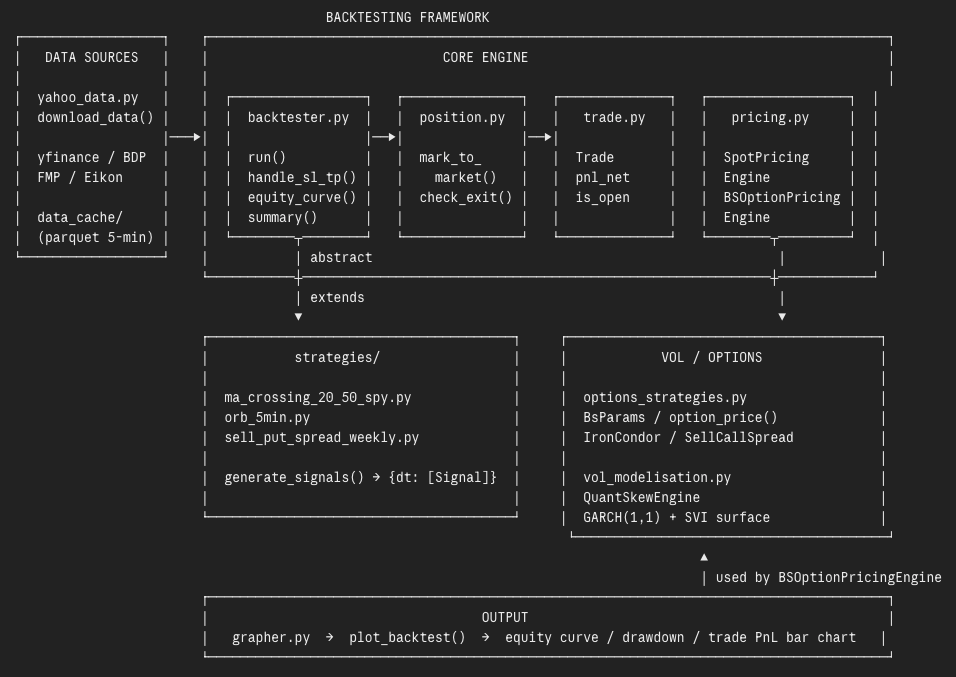
4. L'architecture du framework
L'architecture est organisée en quatre couches, chacune avec une responsabilité unique. Vous n'avez jamais besoin de toucher qu'une seule d'entre elles.
Backtest Framework Chart
La couche DATA SOURCES gère tout ce qui est en amont du moteur : téléchargement des données via yahoo_data.py, normalisation des colonnes, et mise en cache des données intraday en format parquet pour des rechargements rapides. Sources supportées : yfinance, Bloomberg BDP, FMP, Eikon.
Le CORE ENGINE est le cœur du système. backtester.py est la boucle event-driven — elle itère barre par barre, vérifie les stop loss et take profit, ouvre de nouvelles positions sur signal entrant, et marque le portefeuille à la valeur de marché à chaque étape. position.py gère le mark-to-market en temps réel des positions ouvertes. trade.py représente une transaction bookée avec tous ses attributs : prix d'entrée/sortie, P&L brut et net, frais. pricing.py fournit deux moteurs : SpotPricingEngine pour les actions et ETF, BSOptionPricingEngine pour les options pricées en Black-Scholes avec surface de volatilité live.
La couche STRATEGIES est la seule que vous écrivez. Chaque stratégie est une classe Python qui hérite du Backtester ABC et implémente une seule méthode : generate_signals(). Cette méthode reçoit un DataFrame de données de marché et retourne un dictionnaire qui mappe chaque date à une liste de signaux. C'est tout. Le moteur gère le reste : sizing, exécution, P&L, equity curve.
Pour les stratégies sur options, la couche VOL/OPTIONS fournit une stack complète : options_strategies.py avec le pricing Black-Scholes, les classes IronCondor et SellCallSpread, et vol_modelisation.py avec le QuantSkewEngine — un modèle GARCH(1,1) combiné à une surface SVI pour générer une surface de volatilité implicite réaliste à chaque date du backtest.
La couche OUTPUT c'est grapher.py. Un seul appel de fonction — plot_backtest() — produit un rapport en trois panneaux : equity curve indexée à 100 vs benchmark vs taux sans risque, drawdown dans le temps, et P&L par trade en barres avec le P&L cumulé en overlay.
5. Le CLAUDE.md : rendre l'IA native au projet
À la racine du projet se trouve un fichier appelé CLAUDE.md. Quand vous ouvrez Claude Code dans ce dossier, il lit ce fichier en premier — c'est le contexte complet de l'IA pour tout ce qu'elle fait dans ce codebase.
Le CLAUDE.md contient quatre choses. Premièrement, la structure du projet : quels fichiers font quoi, où se trouvent les stratégies, comment s'appellent les classes. Deuxièmement, le contrat de generate_signals() : exactement ce que la méthode doit retourner, date par date, avec des exemples concrets. Troisièmement, une liste d'erreurs documentées à éviter — des pièges rencontrés pendant le développement, écrits explicitement pour que l'IA ne les reproduise pas. Quatrièmement, le protocole step-by-step pour créer une nouvelle stratégie de A à Z. Claude Code suit ce protocole à chaque fois, sans déviation.
Sans le CLAUDE.md, vous devriez réexpliquer le framework depuis le début à chaque session. Avec lui, Claude Code comprend le codebase comme s'il l'avait écrit lui-même — il sait où créer le fichier de stratégie, quelle interface implémenter, comment lancer le backtest, et comment lire l'output.
6. Démo live : MA Crossing 20/50 sur SPY — un prompt, un backtest complet
Voici le prompt exact envoyé à Claude Code :
Dans le folder backtest, peux-tu me générer la stratégie suivante : MA CROSSING SUR 50/20 — long si 20 > 50, short si 20 < 50, SL 2%, TP 15% sur le SPY ETF.
Claude Code lit le CLAUDE.md, identifie la structure du projet, demande les paramètres manquants (période : daily depuis 2000, sizing : capital plein, capital initial : 1 000 000$, frais : 10$ à l'achat / 10$ à la vente, benchmark : S&P 500), génère le fichier de stratégie dans le bon dossier, lance le backtest et sort le rapport complet. Le cycle entier prend moins de 3 minutes.
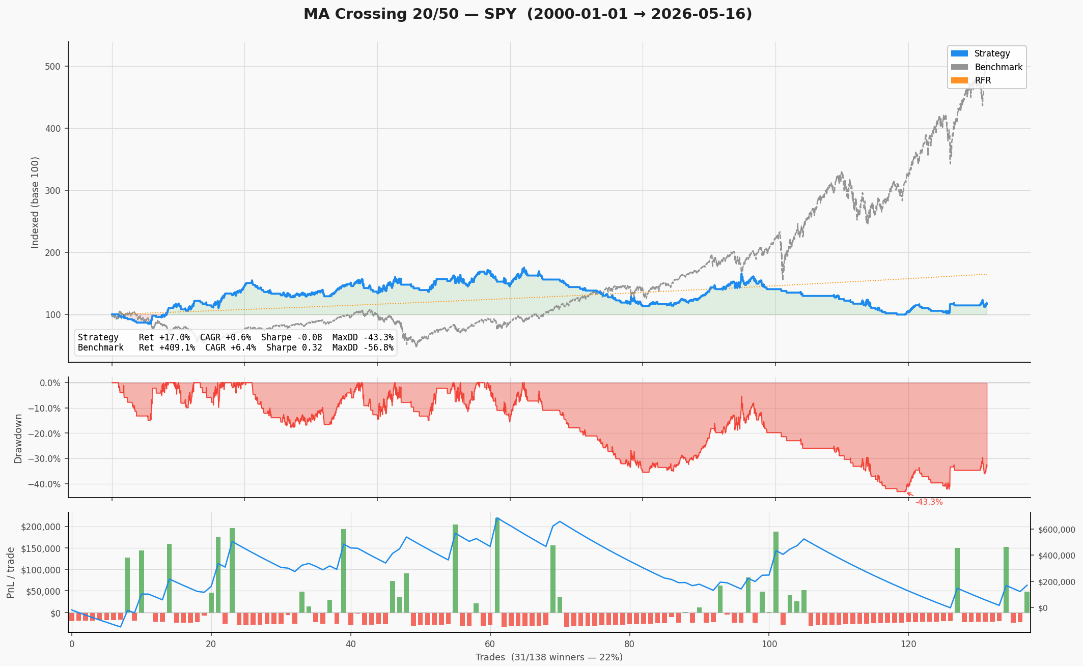
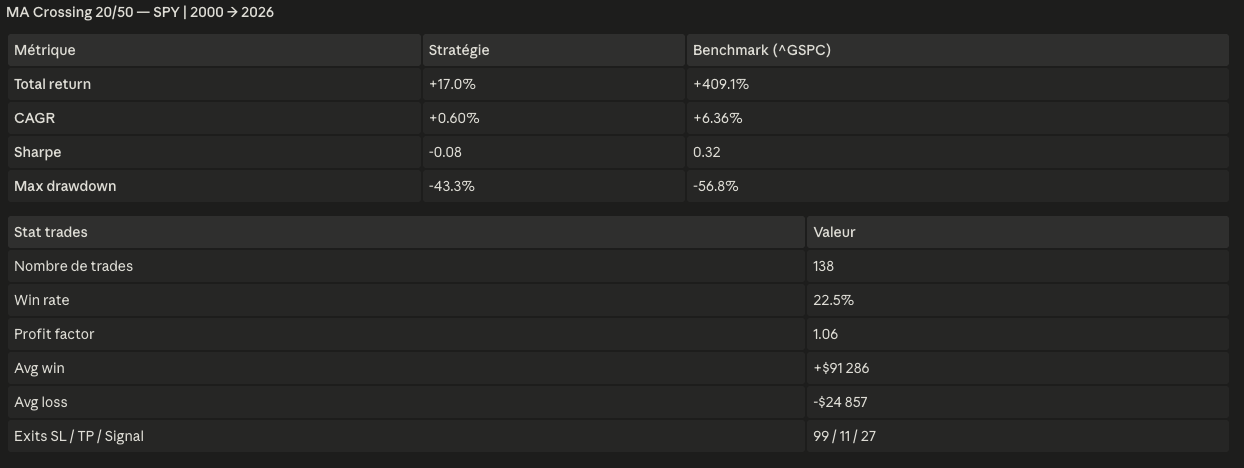
Résultats du backtestRésultats du backtest
Le résultat est instructif précisément parce qu'il est mauvais. La stratégie génère +17,0% de return total sur 26 ans contre +409,1% pour le S&P 500. CAGR de +0,60% vs +6,36%. Sharpe de -0,08. Que dit Claude Code sur ce résultat ? Il le signale immédiatement : le stop loss à 2% est trop serré pour un timeframe daily — le bruit du marché sur une barre journalière dépasse votre stop, donc vous vous faites stopper constamment (99 sorties sur SL sur 138 trades). Le take profit à 15% n'est touché que 11 fois. Le signal en lui-même — le croisement de moyennes mobiles — a une logique, mais les paramètres de risque le détruisent. C'est ça l'étape d'audit : avant même de penser à passer en live, vous comprenez exactement pourquoi la stratégie échoue et ce qu'il faut ajuster.
7. Pourquoi pas Backtrader ou QuantConnect ?
Avant de construire ce framework, j'ai évalué Backtrader, QuantConnect et Zipline. Des frameworks sérieux, bien documentés. Je les ai arrêtés pour deux raisons.
Premièrement : la complexité. Avant de brancher une première stratégie sur Backtrader, vous avez des heures de documentation à lire et un modèle mental imposé par le framework à adopter. C'est bien si vous voulez une solution clé en main. C'est un problème si vous voulez comprendre exactement ce que le moteur fait à chaque barre — et un problème encore plus grand si vous voulez qu'une IA l'utilise couramment.
Deuxièmement, et c'est la vraie raison : aucun de ces frameworks n'est conçu pour être utilisé par une IA. Claude Code a besoin d'un document de contexte clair et explicite. Le CLAUDE.md n'existe pas dans l'écosystème Backtrader ou QuantConnect. Je voulais un framework minimal que je comprends dans ses moindres détails, et que Claude Code peut utiliser comme un outil natif. Donc je l'ai construit — avec Claude Code.
Faut-il savoir coder en Python pour utiliser ce framework ?
Non. Vous décrivez votre stratégie en langage naturel, Claude Code génère le Python. Vous devez pouvoir installer des dépendances Python et ouvrir un terminal — une mise en place de 10 minutes. Après ça, votre input c'est la description de la stratégie, votre output c'est l'equity curve.
Quels instruments le framework peut-il backtester ?
Actions, ETF et indices via Yahoo Finance pour le moteur spot. Stratégies sur options — Iron Condors, put spreads, call spreads — via un moteur Black-Scholes avec une surface de volatilité GARCH + SVI. Les portefeuilles multi-actifs et long/short sont supportés dans la même boucle de backtest.
Le résultat du MA Crossing est mauvais — c'est normal ?
Oui, et c'est le point. Un stop loss à 2% sur un système de croisement de moyennes mobiles en daily est trop serré — le bruit du marché sur une barre journalière est supérieur à votre stop, donc vous vous faites stopper constamment (99 sorties sur SL sur 138 trades). L'étape d'audit du framework le signale immédiatement. L'itération suivante consisterait à élargir le stop ou à le remplacer par un stop basé sur l'ATR, relancer, et comparer. C'est exactement pour ce processus itératif que le framework est construit.
Comment éviter l'overfitting quand on prompte des stratégies à Claude Code ?
L'IA génère le code — elle ne décide pas de la stratégie ni n'optimise les paramètres. Le risque d'overfitting est du côté de l'utilisateur : ne laissez pas Claude Code faire une grid search sur l'ensemble de votre dataset. Définissez une fenêtre in-sample pour la calibration et une fenêtre out-of-sample mise de côté pour la validation. Traitez toute sélection de paramètre faite in-sample comme potentiellement overfit jusqu'à confirmation out-of-sample.
Où trouver le framework ?
Le framework complet incluant le CLAUDE.md est disponible sur la page school de CodeMarketLabs. Téléchargez le dossier, connectez-le à Claude Code, et vous pouvez lancer votre premier backtest dans les 10 minutes qui suivent.